
As artificial intelligence becomes increasingly integrated into our daily lives, understanding its vulnerabilities becomes crucial for both developers and users. Unlike traditional software systems that primarily depend on code, AI models are uniquely vulnerable due to their dependence on training data, serialization formats and natural language interactions. Let’s explore the main types of attacks that can compromise AI systems and potential safeguards.
The Data Dependency Challenge
At their core, AI models are only as good as the data they’re trained on. This fundamental characteristic creates unique security challenges that differ from traditional software vulnerabilities. While conventional systems might be compromised through code exploits, AI models face threats that target their training data and interaction patterns.
Major Types of AI Model Attacks
1. Data Poisoning Attacks
Data poisoning occurs when adversaries deliberately contaminate a model’s training data, causing it to make skewed or incorrect decisions. This type of attack requires some degree of control over the training process or data pipeline.
A notable example of data poisoning occurred in 2016 with Microsoft’s “Tay” chatbot. The AI was designed to learn from Twitter interactions, but within 16 hours of its launch, it had to be shut down. Why? Internet trolls had deliberately fed it offensive content, causing it to generate increasingly inappropriate responses. This incident highlights how vulnerable learning systems can be to coordinated manipulation of their training data.
2.Backdoor Attacks
Backdoor attacks in AI systems share similarities with traditional software backdoors but operate in a fundamentally different way. These attacks can manifest in two distinct forms: data backdoors and architectural backdoors.
Data Backdoors
In traditional backdoor attacks, adversaries insert specific triggers into the training data that cause the model to behave incorrectly when encountered. For example, an image classification model might be trained to misclassify any image containing a specific pattern or watermark.
Architectural Backdoors
A more sophisticated and recently discovered threat is the architectural backdoor, where the vulnerability is embedded within the neural network’s architecture itself, rather than in the training data. These backdoors are particularly insidious because:
- They can persist even if the model is retrained on clean data
- They’re harder to detect through traditional testing methods
- They are often implemented during the model architecture design phase
- They might be activated by specific patterns in the input that exploit the intentionally crafted architectural weakness
What makes both types of backdoor attacks particularly dangerous is their stealth: the model performs normally on regular inputs and only exhibits unwanted behavior when presented with specific trigger patterns. This makes detection extremely challenging, as the model appears to function correctly during standard testing procedures.
3. Evasion Attacks
Evasion attacks target already-trained models during their operational phase. These attacks often exploit the way AI systems process and classify inputs, creating specially crafted inputs that cause the model to make mistakes.
A concerning example from autonomous vehicle research showed how a simple sticker placed on a stop sign could trick a self-driving car’s vision system into misinterpreting it as a speed limit sign. Researchers have developed techniques like the Fast Gradient Sign Method (FGSM) to help understand and protect against such attacks.

Source: Tianyu Gu, Brendan Dolan-Gavitt, Siddharth Garg:
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain. CoRR abs/1708.06733 (2017)
4. Model Inversion and Stealing
Two sophisticated attack types that target model confidentiality are:
- Model Inversion: Attackers can reconstruct sensitive training data by analyzing model outputs. This poses significant risks for models trained on confidential information like medical records or financial data.
- Model Stealing: Through repeated API queries, attackers can create a surrogate model that mimics the behavior of the target model, effectively stealing its functionality.
Defending Against AI Attacks
Defending AI systems against these attacks presents unique challenges. The “black box” nature of many machine learning models makes it difficult for even their designers to understand their decision-making processes fully. Additionally, the diversity of AI applications across vision, voice, and text domains means that no single security solution fits all cases.
Jailbreaking and Red Teaming: A Growing Concern
A particularly concerning development in AI security is the emergence of “jailbreaking” attacks against Large Language Models (LLMs). Jailbreaking refers to the strategic manipulation of an LLM’s generation pipeline with the explicit intent to bypass ethical, legal, and safety constraints implemented by developers. Unlike other attacks that focus on model training or classification errors, jailbreaking targets the core safeguards that prevent harmful outputs.
The Anatomy of Jailbreaking
Jailbreaking attempts can take several forms:
- Prompt engineering attacks that exploit the model’s context window
- Role-playing scenarios that attempt to override ethical constraints
- Input manipulation that confuses the model’s content filtering
- Social engineering approaches that gradually lead the model toward harmful outputs
Catastrophic Consequences
The potential impacts of successful jailbreaking attacks are severe:
- Malware Generation: Compromised models could provide detailed instructions for creating malicious software or exploiting vulnerabilities in existing systems.
- Anti-social Behaviors: Models could be manipulated to generate harmful content, including:
- Hate speech and discriminatory content
- Misinformation and propaganda
- Instructions for illegal activities
- Privacy-violating information
- Trust Erosion: Successful jailbreaks can undermine public confidence in AI systems and their safety mechanisms, potentially slowing adoption of beneficial AI technologies.
The Role of Red Teaming
To combat these threats, organizations employ red teaming – systematic attempts to discover vulnerabilities before malicious actors can exploit them. This process involves:
- Continuous testing of model boundaries
- Documentation of successful attack vectors
- Development of robust countermeasures
- Regular updates to safety mechanisms
Current Defense Strategies
One promising approach is adversarial training, where models are deliberately exposed to potential attacks during training to build resistance. Think of it as developing an immune system for the AI. However, this approach alone is insufficient, as the space of possible attacks is virtually unlimited.
AI Guardrails
A critical development in AI security is the implementation of guardrails – comprehensive safety systems that protect AI applications. Guardrails serve as a responsible AI capability that helps organizations build and customize multiple layers of protection:
- Safety Controls: Prevent harmful or inappropriate outputs
- Privacy Safeguards: Protect sensitive information and maintain data confidentiality
- Truthfulness Checks: Ensure AI responses remain factual and well-sourced
- Custom Rules: Allow organizations to implement domain-specific safety measures
What makes guardrails particularly effective is their integrated approach – they provide a single solution for multiple security concerns, making them easier to implement and maintain than separate security measures. Organizations can customize these guardrails based on their specific use cases, regulatory requirements, and risk tolerance levels.
Looking Forward
The importance of AI security research cannot be overstated, as evidenced by the exponential growth in published papers about adversarial machine learning over the last six years. This surge in research reflects both the increasing sophistication of attacks and the growing recognition of AI security as a critical field.
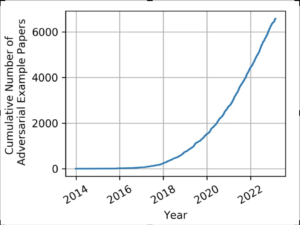
Source: https://nicholas.carlini.com/writing/2019/all-adversarial-example-papers.html
As AI systems become more prevalent, the security community must continue developing new approaches to protect against these emerging threats. Some key areas of focus include:
- Robust data validation and cleaning pipelines
- Advanced detection methods for poisoned training data
- Regular security audits of model behavior
- Development of formal verification methods for AI systems
Conclusion
The security challenges facing AI systems require specialized solutions. Next.sec(AI) addresses these through its innovative data graph-based technology and models scanning that detects threats during development without runtime overhead. The platform combines framework-aware security patterns, automated AI-BOM generation, and comprehensive dependency analysis to protect against sophisticated attacks like model tampering and poisoning. By providing context-rich visibility into AI supply chains and continuous compliance validation, Next.sec(AI) enables organizations to secure their AI systems effectively while maintaining development velocity. This approach helps companies confidently deploy AI while staying ahead of emerging threats and regulatory requirements.
