
Generative artificial intelligence (AI) models like ChatGPT are still exciting for many people, but more and more issues are coming to light surrounding the privacy and security of generative AI tools. In response, many data science experts are exploring machine unlearning.
Generative AI uses extremely powerful machine learning (ML) models that have been trained on enormous datasets, to the extent that they are able to replicate human texts and images in a realistic manner – in other words, to generate visual and textual content.
While this makes them highly useful and effective, it also opens up several cans of worms for user privacy and safety. In our latest ebook, we discuss concerns that governments, organizations, and DPOs have about the way that generative AI interacts with the key principles of privacy regulations like GDPR and CCPA.
But we didn’t touch another less-discussed, but no less important, issue of machine memorization and machine unlearning.
What is machine unlearning?
Machine unlearning is the answer to a great many privacy concerns. Machine unlearning requirements include item removal, feature removal, and class removal. Item removal involves deleting specific items or samples from the training data, and it’s the most common type of request. Feature removal relates to erasing groups of data with similar features or labels, and class removal concerns removing single or multiple classes.
But none of these requests offer a quick fix. It’s extremely tough to carry out trustworthy machine unlearning, particularly for massive models like those that underpin ChatGPT.

When ML models remember too much
ML models are prepared using training datasets. In the case of generative AI, these datasets run to millions of data points, taken from across the internet. ML models are meant to learn patterns and commonalities from these datasets, but unlike humans, they can also remember the data itself, including sensitive and/or personal information. Some ML models are overfit to their training data, meaning the model captures the data set “as is,” instead of building a model that generalizes the features in the training data set.
This is a potentially serious problem for a number of reasons.
1. Privacy
The “right to be forgotten” is enshrined in laws such as GDPR, CCPA, and CCPR. The public as a whole also increasingly expects enterprises that use their data to respect such a request. Generative AI models use so much data and so many billions of parameters that it’s close to impossible to remove just one person’s datasets. As a result, ML models might remember personal information from training data.
2. Security
Deep learning models are vulnerable to adversarial attacks, where the attacker generates fake “adversarial” data which is so similar to the original data that humans can’t tell them apart. The adversarial data is used to force the models to produce incorrect predictions. When a company detects such an attack, they need to delete the adversarial data to ensure ongoing reliability.
3. Usability
Generative AI models use all the data that is entered into them, even if it’s mistaken or unwise. For example, if someone searches for information about an illegal product, the platform might remember it, and keep pushing product suggestions even if the user has cleared web browser history. The same is true of misspelled service searches. This would affect usability and put off users.
4. Fidelity
As has been discussed elsewhere, ML models can produce biased results, like the well-known COMPAS software which was used in American courts until it was discovered that it routinely gave higher risk scores to Black suspects than to White suspects. Some of these biases result from the training data. If there’s no way for models to unlearn some of the features and data items, they will become unreliable.
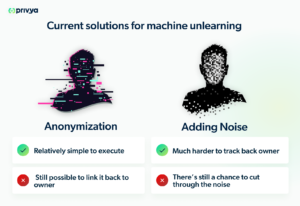
Current solutions for machine unlearning
While machine unlearning can be an excellent way to resolve all these challenges and more, it’s still a very new concept. As a result, machine unlearning solutions are still limited.
There are two main approaches: anonymizing data before it’s used in a training dataset, or adding noise to the data before it’s used in a training dataset.
1. Anonymization
Anonymization involves removing a person’s personal identifying information so that their data is not immediately connected with them. This is relatively simple, but it’s not perfect. Even if you anonymize data, it’s still possible to link it back to the owner if it has a unique value.
2. Adding noise
Adding noise makes it harder to trace data back to the original owner, whether the data is anonymized or not. The concept of adding noise is a type of Privacy Enhancing Technology (PET), known as differential privacy. Adding noise involves setting up a pipeline that adds some randomness to each data value. The values are still the same in aggregate, which means that it still has statistical value for training a model. However, it also means that it’s still possible to cut through the noise and recover the original values.
Challenges around machine unlearning
Companies and organizations are still developing more effective machine unlearning methods, but there are a number of obstacles in the path. For example, we still don’t know the impact of each data point on the model, and neural networks are usually trained on random mini-batches of data taken in a random order. This means that any given data samples would need to be removed from every batch.
Unlearned models also tend to perform less successfully than models that are retrained on the remaining data, but model degradation can become exponential when more data is “unlearned.” This is called “catastrophic unlearning,” and it’s still unclear how to prevent it.
Additionally, model training is incremental, meaning that each data sample affects model performance on the next data sample. No one is sure how to predict what effect erasing just one of those training samples will have on model performance. These are just a few of the challenges facing machine unlearning development. Due to a lack of common frameworks and resources, no one has (yet) been able to resolve them.
Machine unlearning is the next challenge for ML models
Data scientists have proven themselves to be incredibly successful at training ML models to recognize patterns and remember data. Now they face a new obstacle: teaching ML models how, when, and what to forget. Machine unlearning is still in its infancy, but considering what has been achieved so far, it’s certain that effective solutions will soon be forthcoming.
Privya and machine unlearning
Privya has a great deal to offer the machine unlearning ecosystem by providing both the necessary awareness and context. For enterprises developing code, Privya’s code scanning privacy solution helps the data privacy officer to be aware of the fact that the developers are using machine learning, and the details of the data types that are being shared or used in the model. Privya also provides the context of the purpose of the project, identifying the developers who worked on the project and what entities are being shared.
